Ziel dieses Teilprojektes ist es, das VLSI-Entwurfsproblem mit hierarchischen Methoden zu lösen. Im physikalischen Bereich wird dabei ein top-down Ansatz favorisiert. Unser Verfahren soll in der Lage sein, Schaltungen mit mehreren Millionen Gattern auf beliebig vielen Hierarchieebenen zu entwerfen. Der Erfolg des gewählten Verfahrens soll anhand von wirklich großen Papierentwürfen gezeigt werden.
Die entwickelten Methoden werden im PLAYOUT-System, das zur Durchführung der Testentwürfe verwendet wird, implementiert. Neben der Entwicklung verfahrensspezifischer Algorithmen erwies sich die Werkzeugintegration in ein gemeinsames System mit einheitlichem Framework und die Wartung des Systems als immer schwieriger.
Die Durchführung erster Testentwürfe ergab die Forderung nach Verbesserungen innerhalb der Werkzeuge und der Algorithmen. Daneben war der Aspekt des Timings bisher nur unzureichend im PLAYOUT-System gelöst. Es ergab sich daher die Notwendigkeit, auch weiterhin an den Entwurfswerkzeugen zu arbeiten. Am meisten wurde im Berichtszeitraum in den Bereichen Repartitionierung, Chip Planning und Chip Assembly gearbeitet. Der Repartitionierer, der die funktionale Hierarchie einer Schaltung in eine physikalische Hierarchie transformiert, wurde von einem rein interaktiven `Handrepartitionierer' zu einem teilautomatischen Werkzeug weiterentwickelt. Desweiteren wurde hier verstärkt an der Verarbeitung von Zeitkriterien gearbeitet. Im Bereich Chip Planning wurden vor allem die Partitionierungsalgorithmen auf eine bessere Stabilität und Abschätzbarkeit hin näher untersucht. Das Chip Assembly wurde in der Förderungsperiode fertiggestellt. Die letzten Arbeiten in dieser Periode lagen im parallelen Assembly und einer genaueren Kanalbreitenabschätzung. Das PLAYOUT-System wird seit Jahren auch zur Ausbildung von Studenten im Rahmen eines Fortgeschrittenenpraktikums eingesetzt.
Entwurfsabschätzung ist die Vorhersage aller möglichen Entwurfsschritte zu einem möglichst frühen Zeitpunkt. Genaue Schätzungen sollen dabei helfen, kostspielige Iterationen zu vermeiden. Auch in dieser Periode haben wir uns auf den physikalischen Entwurf beschränkt. Wir verbesserten die Schätzung des Zeitverhaltens und des Flächenbedarfs bei vorgegebenen Pinrestriktionen. Die Schätzung der Verzögerungszeiten wurde in den Repartitionierer integriert. Desweiteren wurde an einer Fehleranalyse der Schätzungen gearbeitet.
Repartitionierung ist die Transformation einer vorgegebenen Schaltungshierarchie in eine layoutgerechte, neue Hierarchie. Layoutgerecht bedeutet die Einhaltung von Bereichsvorgaben für die Größe und Zahl der Zellen in einer Hierarchiestufe, eine minimale Zahl der geschnittenen Netze und die besondere Berücksichtigung der zeitkritischen Signalpfade. Für die Repartitionierung bieten sich zwei alternative Ansätze an. Der erste, im PLAYOUT-System realisierte Ansatz, sieht eine interaktive Repartitionierung mit möglichst wenigen Veränderungen der funktionalen Hierarchie vor. In unserer Implementierung trifft der Entwerfer alle Entscheidungen. Die Unterstützung durch den Repartitionierer besteht allein in der Verwaltung der Strukturinformationen und Bereitstellung einiger Analysefunktionen. 1989 war eine einfache Implementierung in PASCAL einsatzbereit. Der zweite Ansatz, den wir auch als Partitionierung bezeichnen, geht von einer flachen Netzliste aus. Die neue Hierachie entsteht dabei durch rekursive Anwendung von Partitionierungsalgorithmen.
Beide Realisierungen zeigten in Beispielentwürfen erhebliche Mängel. In die Hand-Repartitionierung gehen detaillierte Kenntnisse über den Aufbau der Schaltung und die Erfahrung des Entwerfers ein. Dennoch lieferte diese Vorgehensweise schlechte Ergebnisse bzgl. der Größenverhältnisse der Subzellen und der Anzahl der Anschlüsse. Die automatische Partitionierung hingegen löst funktionale Einheiten auf und zerstört die Regularität. In beiden Ansätzen war die Behandlung zeitkritischer Netze unbefriedigend gelöst.
Der Wechesel unserer Rechnerplattform machte eine Reimplementierung der Repartitionierung in C notwendig. Sie wurde 1993 fertiggestellt. Erstmals wurde dabei der Datenstrukturgenerator MOOSE (siehe 3.3.2) zur Generierung der Kerndatenstruktur als abstrakter Datentyp eingesetzt. Der neue Repartitionierer wurde um einfache Strategien, zum Beispiel "löse Blöcke mit weniger als n Standardzellen flach auf" und um eine Analyse des Zeitverhaltens erweitert [Sol91.1], [HNZ93], [Nuh92]. Damit war erstmals die Voraussetzung zur Zeitbehandlung in der Repartitionierungsphase geschaffen. Zeitgesteuerte Partitionierungsalgorithmen scheitern bei großen Entwürfen an der Laufzeitkomplexität. Wir verfolgen daher den Ansatz, den Entwerfer durch Analysefunktionen mit graphischer Darstellung der Analyseergebnisse zu unterstützen [Hof93]. Basierend auf der Analyse wurde eine Komponente implementiert, die dem Entwerfer für die schrittweise Modifikation der Hierarchie Vorschläge unterbreitet. Darüber hinaus wurde die Möglichkeit geschaffen, in einem Floorplan zu repartitionieren [Bur93].
Der Vorteil der Repartitionierung im Floorplan liegt darin, daß der Entwerfer die Größenverhältnisse der Subzellen einer Zelle sofort erkennt. Darüber hinaus sorgt die zeitgesteuerte Plazierung dafür, daß Subzellen, die aufgrund von Zeitbedingungen oder der Zahl ihrer Verbindungen zusammengehören, im Floorplan benachbart sind und bevorzugt zu Clustern zusammengefaßt werden. Im Prinzip verknüpfen wir damit die Ansätze der automatischen Partitionierung und der interaktiven Repartitionierung.
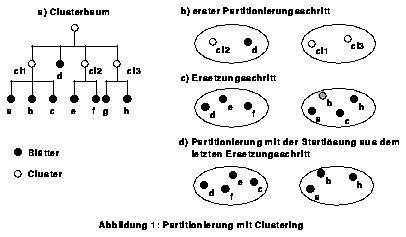
Die Topographie des Floorplan erzeugen wir wie im Chip Planner mit Bipartitionierung, Horizontal/Vertikal-Orientierung (H/V-Orientierung) und Links/Rechts-Ordering (L/R-Ordering). Zur Bipartitionierung verwenden wir den Ansatz von Fiduccia und Mattheyses mit der Ratio-Cut Kostenfunktion (FMRPart). Tests zeigten, daß die Ergebnisse bei kleinen änderungen stark voneinander abweichen. Wir bilden daher entsprechend dem Ansatz von Cong und Smith [CoS93] zunächst durch bottom-up Clustering einen n-ären Clusterbaum (siehe Abbildung 1), partitionieren mit FMRPart die Söhne der Wurzel im Clusterbaum und ersetzen dann die Elemente der Partitionen wiederum durch ihre Söhne im Clusterbaum. Alternierend setzen wir Partitionierung und den Ersetzungsschritt bis zu den Blättern des Clusterbaumes fort. Das Ergebnis sind zwei Partitionen, die wiederum nach der gleichen Strategie bipartitioniert werden [Bin94]. Sizing liefert anschließend die H/V-Orientierung und eine stochastische Abschätzung der Verdrahtungsfläche. L/R-Ordering erzeugen wir mit einem genetischen Algorithmus [Bur93].
Zeitkriterien berücksichtigen wir bei der Erzeugung des Floorplan in der Bipartitionierung und im L/R-Ordering. In der Bipartitionierung gehen die Zeitkriterien in Form von Netzgewichten ein . Jedes Individuum aus der Population des genetischen Algorithmus zur Bestimmung des L/R-Ordering ist eine mögliche Lösung des Problems, in unserem Fall ein gültiges L/R-Ordering für den Partitionsbaum. D. h., es ist jederzeit die vollständige Topographie der Schaltung bekannt. Die Netzverläufe der zeitkritischsten Netze können also abgeschätzt werden und gehen in die Fitneßfunktion ein.
Ein erster Entwurf hat gezeigt, daß die Floorplan-Repartitionierung hilft, die Entwurfszeiten zu verkürzen. Unser Ziel war es, eine Beispielschaltung in ca. 20 Partitionen zu strukturieren. Ein geübter Entwerfer löst diese Aufgabe jetzt in weniger als 30 Minuten, wofür mit der älteren Implementierung einige Tage benötigt wurden.
Unser PLAYOUT Chip Planner besteht aus einer Kerndatenstruktur, verschiedenen Algorithmen zur Plazierung, zum Sizing und zum Global Routing sowie einer graphisch-interaktiven Oberfläche mit Analysefunktionen und Kommandoprozessor.
Das Konzept der Kerndatenstruktur wurde seit dem letzten Berichtszeitraum wesentlich modifiziert. Anstelle der manuellen Umsetzung der entworfenen ER-Modelle in ablauffähige PASCAL-Programme sind wir dazu übergegangen, aus einem gemeinsamen Datenmodell die Datenhaltungskomponente für das Werkzeug zu generieren (siehe 3.3.2). Der Generator unterstützt eine objektorientierte Modellierung und erzeugt C++-Code. Zusammen mit der Erweiterung der Planungsalgorithmen um Timing-Kriterien und dem Umstieg auf eine neue Hardwareplattform ergab sich der Zwang zu einer Neuimplementierung. Das Redesign des Chip Planners wird dazu genutzt, die graphisch-interaktive Oberfläche und den Kommandoprozessor objektorientiert zu verwirklichen. Später sollen auch diese Komponenten mit Generierungsmethoden erzeugt werden. Als Basis dafür wurden zwei projektspezifische, objektorientierte Bibliotheken für User-Interface-Komponenten [Hau93] und zweidimensionale Graphik [Wis93] entworfen und implementiert. Diese Bibliotheken sind erweiterungsfähig ausgelegt und bilden einen Beitrag zu den Arbeiten in B7.
Die Bibliothek für User-Interface-Komponenten baut auf dem OSF/Motif-Standard auf. Sie enthält Klassen, die graphische und nicht-graphische Bausteine von Benutzeroberflächen modellieren. Die graphischen Bausteine umfassen Klassen zur Verwaltung von ein oder mehreren Hauptfenstern der Applikation mit optionaler Menüleiste, von Dialogfenstern zur Ausgabe von Statusmeldungen und zur gesicherten Eingabe von Parameterwerten sowie Klassen zum Auslösen von Aktionen. Zu diesen Aktionen gehört zum Beispiel das Anstoßen der CAD-Algorithmen. Es kann aber auch jede andere Anwendungsfunktion in speziellen Kommandoklassen gekapselt werden. Die Kommandoklassen besitzen einen mehrstufigen Undo-Mechanismus und bilden ein Beispiel für nicht-graphische User-Interface-Komponenten. Schließlich wurde über sogenannte Zeichenfenster die Verbindung zu einer einfachen Integration von X11-Graphiken geschaffen.
Für die zweidimensionale Farbgraphik des Chip Planners wurde eine auf dem X11-Windowsystem aufbauende Bibliothek verfaßt, die neben einfachen graphischen Objekten (Linie, Kreis, Rechteck) auch komplexe kennt (Flächenpläne, Slicingbäume, Statistiken in Form von Histogrammen und Funktionsplots). Neben der Kapselung der Graphikinitialisierung und der Hardwareabhängigkeiten sowie der durchgehenden Verwendung von Weltkoordinaten anstelle von Bildschirmkoordinaten bietet die Bibliothek für alle Graphikobjekte Methoden zum Verschieben, Drehen, Speichern, Drucken, Zoomen und Gruppieren an.
Die von unserem Chip Planner durchgeführte Flächenplanung besteht aus Algorithmen zur Plazierung, zum Sizing und zum Global Routing. Die Plazierung teilt sich in topologisches Plazieren und anschließendes Sizing zur Berechnung einer gültigen Topographie auf. Das topologische Plazieren besteht wiederum aus den Teilschritten Partitionierung zur Erzeugung einer Slicingstruktur, Festlegen der Schnittrichtungen der Slicinglinien (H/V-Orientierung) und L/R-Ordering. Das Sizing geschieht durch Hochrechnen der Flächenkurven entsprechend der Slicingstruktur. Für das Global Routing wird ein Verfahren verwendet, das für die zu verlegenden Netze sukzessive Steinerbaum-Heuristiken auf erweiterten Channel Intersection Graphen durchführt. Ergebnisse des Global Routing sind die Kanalbreitenberechnung, die Zuordnung von Verdrahtungsstrecken zu Kanälen und die Vorgabe von Pinintervallen für die Planungsschritte auf der nächsttieferen Hierarchieebene.
Man erkennt, daß bei der vom Chip Planner durchgeführten Flächenplanung teilweise dieselben oder ähnliche (auf genaueren Daten arbeitende) Algorithmen wie bei der Repartitionierung im Floorplan (siehe 3.1.1) zur Anwendung kommen. Hier bietet sich die Verwendung von unseren Programmbibliotheken an, um die Wiederverwendbarkeit der Algorithmen ohne doppelte Programmierung zu ermöglichen.
Bei den Partitionierungsalgorithmen sind wir dazu übergegangen, mit der Ratio-Cut-Partitionierung, wie sie von Cheng/Wei vorgeschlagen wurde [ChW91], ein weiteres Verfahren in den Chip Planner einzubringen. Die Ratio-Cut-Partitionierung berücksichtigt in ihrer Kostenfunktion neben der Anzahl der geschnittenen Netze auch die Balance der Partitionen und tendiert dadurch eher als beispielsweise die Fiduccia/Mattheyses-Heuristik dazu, natürliche Partitionen zu finden. ähnliches kann man bei der Fiduccia/Mattheyses-Heuristik durch abgeschwächte Ausgewogenheitsbedingungen erreichen. Ein anderer Vorteil der Ratio-Cut-Partitionierung ist, daß in der Initialisierungsphase schon mit einer simplen Heuristik versucht wird, eine gute Startlösung zu finden. Hier untersuchen wir gerade, ob durch Aufnahme dieser Heuristik in die Fiduccia/Mattheyses-Partitionierung dort die Notwendigkeit entfällt, viele zufällige Startlösungen zu generieren, um ein gutes Ergebnis zu erhalten. Der wesentliche Unterschied ist dann noch, daß der Cheng/Wei-Algorithmus eine Gruppierungstechnik anwendet, die eng vernetzte Schaltungsteile zusammenfaßt. Wichtig ist bei unseren Untersuchungen stets die Verbesserung der Abschätzbarkeit und Stabilität der Ergebnisse, da unser top-down Entwurf auf Schätzungen beruht (siehe 3.2).
Bei der Modellierung des Zeitverhaltens im Chip Planner verfolgen wir ähnliche Konzepte wie im Repartitionierer. Netze auf zeitkritischen Pfaden werden in der Partitionierungsphase stärker gewichtet, um sie möglichst in einer Partition zu halten. Die H/V-Orientierung erfolgt durch Ermittlung der optimalen Schnittrichtungen aus den Flächenpunkten der aufaddierten Shape Function der CUD. Mit CUD (Cell Under Design) bezeichnen wir die Zelle, die von einem Entwurfsalgorithmus gerade bearbeitet wird. Da in guten Partitionierungen die Schnittrichtungen meist abwechseln, sollte es allein durch das L/R-Ordering möglich sein, geometrische Nähe für die Zellen auf den zeitkritischen Pfaden zu erzielen. Beim L/R-Ordering tritt damit zum Optimierungsziel der Minimierung der Gesamtverdrahtungslänge das Einhalten aller Zeitbedingungen als wichtige Nebenbedingung. Um dieses garantieren zu können, integrieren wir Global Routing Algorithmen, insbesondere für die zeitkritischen Netze, in diese Phase.
Der Chip Planner war Kernstück bei einem Testentwurf (als Papierentwurf) mit 280.000 Standardzellen [Sur92]. Die Schaltung wurde in drei Hierarchieebenen partitioniert und sollte die Qualität von hierarchischen top-down Entwürfen zeigen. Auch wenn heute einige nicht-hierarchisch arbeitende CAD-Systeme wie z.B. Gordian/Domino und TimberWolf bestimmte Schaltungstypen dieser Größenordnung beherrschen, so bietet der hierarchische Ansatz doch weiterhin zwei Vorteile. Zum einen beherrscht unser Ansatz immer Schaltungen, die um Größenordnungen komplexer sind, als die aktuelle Obergrenze nicht-hierarchischer Werkzeuge (was mit unserem Testentwurf 1991 gezeigt wurde), da unser Verfahren keine Beschränkungen bezüglich der Größe der Blöcke auf unterster Hierarchieebene hat. Zum anderen erlaubt der hierarchische Ansatz die Mischung von flexiblen Zellen, Multimakrozellen und Makrozellen. Das Layout von flexiblen Zellen wird erst nach der Flächenplanung mit den dort ermittelten Flächen- und Pinvorgaben synthetisiert. Bei Multimakro- und Makrozellen steht das Layout zu Beginn des Entwurfs fest. Sie unterscheiden sich darin, daß es zu einer Multimakrozelle mehrere Layoutalternativen gibt.
Das 3-Phasen Chip Planning wurde von uns entwickelt, nachdem Messungen gezeigt haben, daß Abweichungen von den Flächenabschätzungen bis zu 10 % unvermeidbar sind [SAZ92] und damit die Vorteile des top-down Ansatzes zunichte machen können. Um dies zu vermeiden, führen wir beim 3-Phasen Chip Planning [ASZ93] neben dem Planungsschritt der einfachen top-down Planung (Phase α) Anpassungsschritte an eine verfeinerte Rahmenbeschreibung (in der Phase ß) und an die verfeinerten Daten der Subzellen (in der Phase γ) aus (siehe Abbildung 2). Da nicht notwendigerweise die Phase α für alle Subzellen durchgeführt werden muß, bevor ein Abgleich mit der CUD erfolgt, existieren verschiedene Strategien des 3-Phasen Chip Planning, die in den angegebenen Publikationen näher untersucht wurden.
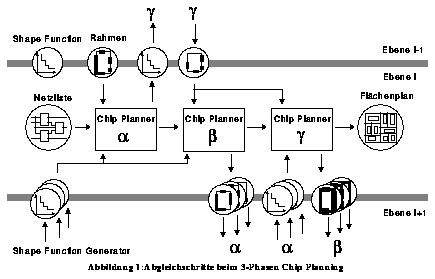
Abbildung 1: Abgleichschritte beim 3-Phasen Chip Planning
Beim unsererm Testentwurf wurden 80 Planungsschritte mit dem Chip Planner und über 600 Zellsyntheseschritte durchgeführt. Der Flächengewinn gegenüber der einfachen top-down Methode betrug beim 3-Phasen Chip Planning ca. 7 % auf der obersten Hierarchieebene. Einige Zellen der zweiten Hierarchieebene wurden ebenfalls auf die erzielbaren Flächeneinsparungen hin untersucht. Hier zeigte sich ein Unterschied zwischen Zellen, die fast nur flexible Subzellen hatten und solchen, die viele Makro- oder Multimakrozellen enthielten. Bei ersteren verbesserte die 3-Phasen Methode die Fläche um 4 bis 10 %, während bei letzteren sich praktisch keine Verbesserungen einstellten. Die Begründung dafür ist, daß die Flächenpläne für Zellen mit vielen Makrozellen als Subzellen bei den ersten Planungsschritten (α und ß) recht viel Verschnittfläche enthielten, die zur Kompensation genutzt werden konnte für die Fläche, die benötigt wurde für die Subzellen, die größer als abgeschätzt ausfielen.
Zur Ausführung eines Entwurfs dieser Komplexität war die Datenverwaltungskomponente des PLAYOUT-Systems ein notwendiges Hilfsmittel. Weitere Unterstützung für unsere Entwürfe versprechen wir uns durch die Arbeiten zu Design Management Systemen, die zur Zeit in unserer Arbeitsgruppe laufen.
Mit der Dissertation Klaus Glasmacher [Gla92] wurden die Arbeiten am Chip Assembly im wesentlichen beendet. Neue Erkenntnisse brachte uns hier die Idee der konkurrenten Layout-Synthese. Bei der hierarchischen Layout-Synthese ist das Gesamtergebnis abhängig von der Reihenfolge der Teilsynthesen. In [Gla92] wird ein Verfahren zur konkurrenten Synthese von Standardzellblöcken vorgestellt. Für jeden Zellblock (Subzelle der zu synthetisierenden CUD) wird ein eigener Syntheseprozeß erzeugt. Diese Prozesse werden auf einzelne Rechner verteilt und steuern sich gegenseitig durch Austauschen von Constraints (constraint propagation). Welche Zellblöcke Constraints austauschen, wird durch einen Nachbarschaftsgraphen bestimmt, der sich als Ergebnis des Chip Planning aus dem Floorplan eindeutig aufstellen läßt. Als Constraints werden die resultierenden Flächen der Teilsynthesen, sowie die Netzlänge gewählt. Diese Kriterien dienen auch anschließend der Bewertung des Layouts der CUD. Die Pinpositionen auf den Rändern der Subzellen können durch die konkurrente Synthese gut aufeinander abgestimmt werden. Mit diesem Verfahren konnte gezeigt werden, daß die Qualität der Layouts auf Chipebene signifikant zunimmt. Für Testbeispiele wurde im Durchschnitt ein Flächengewinn von 5% und ein Gewinn in der Netzlänge von 7% erreicht. Durch die parallelen Syntheseprozesse konnte die Entwurfszeit verkürzt werden. Der Kommunikationsaufwand kann vernachlässigt werden.
Des weiteren wurden einzelne Algorithmen im Chip Assembly verbessert, sodaß das Entwurfswerkzeug Chip Assembly einen Entwicklungsstand erreicht hat, der eine erfolgreiche Validierung der Planungsergebnisse zuläßt. Ein Problem bestand in der Anpassung der globalen Verdrahtung an geometrische Kanalstrukturen [Que91]. Um die globale Verdrahtung aus der Planung zu verwenden, mußte diese an die Anforderungen des Chip Assembly angepaßt werden. Probleme ergaben sich zum Beispiel durch die Verwendung von Rectagonen im Chip Assembly, während bei der Planung nur rechteckige Zellformen zulässig sind.
Für eine Optimierung der Zellfläche im Chip Assembly, welche sich als Kompaktierungsproblem mit variablen Abstandsregeln auffassen läßt, wurde ein auf Distanzfunktionen benachbarter Subzellen basierendes Verfahren entwickelt [GHZ91.1]. Eine Distanzfunktion definiert den Mindestabstand zweier Zellen innerhalb eines vorgegebenen Verschiebungsbereichs. Die hypothetischen Verschiebungen zu den im Floorplan erzeugten Ausgangspositionen erfolgen stets in Richtung des Slices, der zwischen den Zellen liegt. Für jede Verschiebung wird die notwendige Distanz (Abstand) der Zellen orthogonal zum Slice berechnet. Das auf einem genetischen Algorithmus aufgebaute Optimierungsverfahren (2-dimensionale topologische Kompaktierung) wurde erfolgreich implementiert. Es hat sich jedoch gezeigt, daß die bis dahin verwendeten Distanzfunktionen zu erheblichen Fehlern führen können, da sie lediglich auf der Dichte eines durch zwei benachbarte Zellen definierten Kanals aufbauen. Deshalb wurde ein neues Verfahren zur Berechnung der Distanzfunktionen entwickelt und implementiert [Bec93]. Wir führten Distanzfunktionen für den Bereich zwischen drei und vier Zellen ein, die genauere Abschätzungen der Verdrahtungsfläche für diese Fälle ermöglichen. Außerdem erhielten die Distanzfunktionen einen Parameter, der den Typ des zu verwendenden Routing-Modells (z.B. Manhattan oder Knock Knee) berücksichtigt. Damit konnte die Möglichkeit des Gebrauchs verschiedener Router mit in die Optimierung einbezogen werden. Die Optimierung wurde auf die neuen Distanzfunktionen hin angepaßt. Ergebnisse unterschiedlicher Testbeispiele haben gezeigt, daß die so abgeschätzten Kanalflächen und somit die Gesamtfläche des Layouts bis auf wenige Ausnahmen der tatsächlich verdrahteten Fläche gleichen. Ebenso können bei der Optimierung die Netzlängen innerhalb der Kanäle mit betrachtet werden.
Das Chip Assembly wird als Validierungswerkzeug für unsere Planung und Abschätzung häufig und erfolgreich eingesetzt. Für große Testentwürfe konnten Annahmen über das reine top-down Chip Planning und 3-Phasen Chip Planning bestätigt werden. Hier konnten wir zeigen, daß die Fläche des Layouts von der abgeschätzten Fläche des Floorplan nur gering abweicht.
Um die Flächenabschätzung weiter zu verbessern, wurden viele reale Entwürfe durchgeführt. Die Ergebnisse zeigten, daß die Flächenabschätzung der Standardzellplazierung hinreichend genau ist. Um hier eine zusätzliche Verbesserung zu erreichen, wurde in [Xin92] ein Verfahren vorgeschlagen, das mit statistischen Methoden die Parameter der Flächenabschätzung justiert. Ausgangspunkt für diese Untersuchungen waren ebenfalls eine Reihe von Entwürfen, die die Basis für die statistischen Annahmen lieferten. Es wurde gezeigt, daß der Flächenfehler (Abweichung zwischen Schätzung und Realisierung) normalverteilt ist. Da die Parameter proportional in die Abschätzung eingehen, lassen sich diese anhand der Fehleranalyse leicht korrigieren. Die Anpassung der Parameter ist ebenfalls allein durch statistische Methoden erreichbar.
Desweiteren hat sich gezeigt, daß der Einfluß der Pinverteilung auf dem Rand der Zellen nicht zu vernachlässigen ist. Bisher wurde für die Flächenabschätzung eine Gleichverteilung der Pins auf dem Rand der Zellen angenommen. Um den Einfluß der Pinverteilung zu untersuchen, wurden Standardzellplazierungen mit verschiedenen Einschränkungen für die Lage der Pins durchgeführt. In [Xin92] und [SuZ92] wird der Einfluß der Pinverteilung auf die Flächenabschätzung beschrieben. So läßt sich während der Chip Planning Phase der zusätzliche Flächenbedarf der Subzellen durch Einschränkung der Pins in Intervalle bestimmen. Bei der bottom-up Berechnung der Flächenfunktionen werden für den Flächenbedarf der Netze nur die Netze betrachtet, die innerhalb der jeweiligen Zelle verlaufen (interne Netze). Für die Netze, die Subzellen auf der nächsthöheren Hierarchieebene verbinden (externe Netze), muß während der top-down Planung ein zusätzlicher Flächenbedarf mit eingerechnet werden. Hier hat sich gezeigt, daß dieser Flächenbedarf stark von der Pinverteilung abhängt und somit zu einem nicht linearen Netzaufschlag führt. Während der Förderungsperiode war die Einführung der strikten Trennung interner und externer Netze für die Flächenabschätzung Grundlage vieler Untersuchen und hat zu guten Ergebnissen geführt.
Für das Entwurfssystem PLAYOUT wurde begonnnen, ein Modell zur statistischen Analyse und Ermittlung der natürlichen Schwankungen (Toleranzen) der Entwurfswerkzeuge und damit des Entwurfsprozesses zu entwickeln. Ziel ist es hier, Entwurfsentscheidungen des Entwerfers zum frühestmöglichen Zeitpunkt zu unterstützen (z.B. durch Auswahlkriterien für verschiedene Schaltplanalternativen während der Struktursynthese) bzw. ungünstige Entwurfsentscheidungen so früh wie möglich zu erkennen. Dies ist nicht mit absoluter Genauigkeit möglich, sodaß die Unterstützung auf Basis statitischer Größen erfolgen muß. Mit Fortschreiten des Entwurfsprozesses nimmt der Fehler von Entwurfsentscheidungen ab. Wird z. B. in der Struktursynthese eine Abschätzung der Fläche und des Laufzeitverhaltens vorgenommen, so sind Entwurfsentscheidungen aufgrund dieser Abschätzung mit relativ großem Fehler behaftet. In der Layoutsynthese dagegen lassen sich sehr genaue Abschätzungen der Fläche und des Laufzeitverhaltens durchführen. Erste quantitative Ergebnisse bezüglich der Schwankungen, Toleranzen und Stabilität unserer Werkzeuge erwarten wir gegen Ende dieser Förderungsperiode.
Unser Modell zur Flächenabschätzung soll in B6 zur flächenorientierten Logikminimierung Verwendung finden.
Bereits 1987 ist es mit der Fertigstellung des Flächenfunktionsgenerators gelungen, Voraussagen über den Flächenbedarf des Layouts einer VLSI-Schaltung zu machen, ohne einen prototypischen Entwurf durchzuführen. Frühe Aussagen über das Zeitverhalten einer VLSI-Schaltung vor dem Layout waren dagegen bisher nicht möglich. Mit Fortschreiten der Technologie und damit ansteigenden Entwurfskosten und der Forderung nach immer schnelleren Schaltungen gewinnt die Abschätzung des Zeitverhaltens zunehmend an Bedeutung. Die Aufgabe der Abschätzung des Zeitverhaltens ist jedoch weitaus schwieriger als die Flächenabschätzung. Der Flächenfunktionsgenerator schätzt die Verdrahtungslängen der Netze und die daraus resultierende Fläche stochastisch ab. Statistisch gesehen bestehen zwar Korrellationen zwischen Netzlängen, Verdrahtungsflächen und Verzögerungen auf Netzen, aber die maximal mögliche Taktfrequenz eines synchronen Automaten hängt nicht von der mittleren Verzögerung, sondern von der Länge des längsten (kritischen) Logikpfades zwischen zwei Speicherelementen ab. Gibt man die strenge Synchronität auf, so geht es um mehrere kritische Pfade zwischen gleichgetakteten Speichergruppen, zum Beispiel Registern.
In jedem Fall muß es das Ziel sein, die Länge des oder der kritischen Pfade(s) zu minimieren, nicht nur die mittlere Pfadlänge. Hier treten mehrere Schwierigkeiten auf. Ob ein Pfad kritisch ist, läßt sich erst aus dem detaillierten Layout berechnen. Dadurch entstehen kostspielige Iterationen. Sobald ein Pfad minimiert ist, wird sofort ein anderer kritisch. Man muß deshalb versuchen, die "criticality" aller Pfade vor dem Layout abzuschätzen, um dann die kritischsten entsprechend zu berücksichtigen. Die Abschätzung des Zeitverhaltens beinhaltet damit zwei Aufgaben: Erstens soll die maximale Taktfrequenz einer Schaltung in einem frühen Entwurfsstadium möglichst genau ermittelt werden. Zweitens sollen die zeitkritischsten Pfade bzw. Netze der Schaltung zur Steuerung der folgenden Entwurfsschritte ermittelt werden.
Die Signallaufzeiten auf Logikpfaden zwischen zwei Speicherelementen setzen sich aus je einem konstanten und einem variablen Anteil zusammen. Der konstante Anteil der Pfadverzögerungszeit ergibt sich aus der Summe der Signalverzögerungen innerhalb der Basiszellen auf einem Pfad. Lastabhängige Verzögerungen der Basiszellen (Blätter im Hierarchiebaum) und Signallaufzeiten auf den Netzen eines Pfades bilden den variablen Anteil. Eine Abschätzung des variablen Anteils ist eng mit der Flächenabschätzung und einer darauf basierenden Abschätzung der Netzverläufe verbunden. Zur Abschätzung des Zeitverhaltens nutzen wir die Schaltungshierarchie aus. Basierend auf der Flächenabschätzung der Subzellen erzeugen wir auf der obersten Ebene einen Floorplan und planen die globalen Netzverläufe. Aus den Netzverläufen ermitteln wir RC-Bäume zur Bestimmung der resultierenden Verzögerungszeiten. Signalverzögerungen der Netze der unteren Hierarchieebenen haben auf das Zeitverhalten der Schaltung geringeren Einfluß als die langen Netze der obersten Hierarchieebene. Ihre Längen werden statistisch aus dem abgeschätzten Umfang der Zelle ermittelt und ihr Zeitverhalten hinreichend exakt nur durch Kapazitäten modelliert.
Neben den Signalverzögerungen auf den Logikpfaden hat der Takt-Skew entscheidenden Einfluß auf das Zeitverhalten. Takt-Skew kann durch ungeeignete Taktverdrahtungsstrategien oder durch Toleranzen im Herstellungsprozeß entstehen. Das Verdrahtungsproblem löst der Zero-Skew-Algorithmus von Tsay [Tsa93]. Die Toleranzen im Herstellungsprozeß lassen sich nicht beseitigen. Sie müssen aber zur Bestimmung der maximalen Taktfrequenz näherungsweise bestimmt werden. Der fabrikationsbedingte Takt-Skew ist abhängig von der Länge des oder der Taktverteilungsnetze(s). Wir planen daher die Taktverteilung im Floorplan der obersten Schaltungshierarchieebene und leiten daraus den Takt-Skew ab.
Nach der Berechnung der Signalverzögerungszeiten und des Takt-Skew erfolgt die Taktplanung. Ziel ist die Bestimmung der optimalen Taktzeitpunkte der Speicherelemente. Unser Verfahren [Nuh92] erlaubt die Verwendung verschränkter Takte. Damit lassen sich unter bestimmten Bedingungen synchrone Schaltwerke mit asymmetrischem Takt erheblich beschleunigen. Unser Verfahren erlaubt darüber hinaus die gemischte Verwendung von Latches, D-Flip-Flops oder Master-Slave Latches in einer Schaltung.
Das Ergebnis unserer Beispielentwürfe in der vorangegangenen Förderungsperiode ist eine Vielzahl von Layouts, die uns eine Validierung der Flächenabschätzung ermöglichen. Zur entwurfsbegleitenden Zeitbehandlung können wir eine Abschätzung des Zeitverhaltens einer Schaltung durchführen und Steuerungsmechanismen für die zeitgesteuerte Planung bereitstellen. Bisher fehlte uns aber die Möglichkeit der Validierung der Abschätzung. Wir haben daher eine Timing-Analyse für Makrozellen (zunächst nur für synthetisierte Standardzellblöcke) implementiert [Web92]. Damit lassen sich Zweiebenenentwürfe wie folgt validieren. Nach der Layoutsynthese der Standardzellblöcke und der Makro-Timing-Analyse ist das Layout und das Zeitverhalten der Subzellen exakt bekannt. Es wird nun der Floorplan der Abschätzung unter Beibehaltung der Topologie an die Layouts der Subzellen angepaßt und die globale Verdrahtung wegen der jetzt bekannten Pinpositionen der Subzellen wiederholt. Alle Verzögerungen von Signalnetzen und Taktverteilungsnetzen lassen sich jetzt durch RC-Bäume modellieren und mit denen der Abschätzungsphase vergleichen. Erste Meßergebnisse sollen noch in dieser Förderungsperiode vorliegen. Als Beispielentwürfe verwenden wir eigene Schaltungen und Schaltungen, die in B5 entstehen. Diese sind ausreichend komplex für einen hierarchischen Entwurf und aus der Sicht des Timings besonders interessant, da hier hierarchische Mehrphasen-Taktsysteme zum Einsatz kommen.
Mirror sites:


