Die Entwicklung der aktuellen Visualisierungsarchitektur hat sich dabei im Laufe der Zeit als so interessant herausgestellt, daß sich aus einer reinen Beispielarchitektur ein eigenständiges Forschungsprojekt entwickelte.
Die entwickelten Methoden zur Lösung des VLSI-Problems wurden im PLAYOUT Prototyp-Entwurfssystem implementiert. Neben der Entwicklung verfahrensspezifischer Algorithmen erwies sich die Werkzeugintegration in ein gemeinsames System mit einheitlichem Framework und die Wartung des Systems als immer schwieriger, so daß sich ein großer Teil der Forschung in B4 verstärkt mit der ECAD-Framework-Problematik beschäftigte. Das PLAYOUT-System wurde zur Durchführung mehrerer großer Testentwürfe herangezogen.
Im Laufe der gesamten Förderungszeit gliederte sich das Teilprojekt B4 in vier Teilaufgaben, wovon im aktuellen Berichtszeitraum noch drei Teilaufgaben bearbeitet wurden. Die letzten Arbeiten der langfristigen Teilaufgabe "PLAYOUT-Werkzeuge" wurden in der letzten Förderungsperiode im Rahmen der Teilaufgaben "Abschätzung und Planung" sowie "Entwurfsmanagement und Werkzeugintegration" durchgeführt.
Aufgabe I: Abschätzung und Planung
Entwurfsabschätzung ist die Vorhersage aller möglichen Entwurfsschritte
zu einem möglichst frühen Zeitpunkt.
Sie soll dazu dienen, kostspielige Iterationen zu vermeiden.
Im Rahmen unseres Chip-Planning-Ansatzes haben wir wesentliche Beiträge
zur Flächenabschätzung und zur Abschätzung des Zeitverhaltens geleistet.
Das entwickelte Schätzverfahren ist eng verknüpft mit dem
von uns entwickelten und implementierten Chip Planner
sowie mit einer verfeinerten Planungsmethode, die wir 3-Phasen Chip-Planning nennen.
Eine lauffähige Implementierung fanden diese Arbeiten im PLAYOUT Prototyp-Entwurfssystem.
Im aktuellen Berichtszeitraum wurde in dieser Teilaufgabe im wesentlichen
an einer Fehleranalyse der Schätzungen,
an einer verbesserten Behandlung des Zeitverhaltens
und an einer Verbesserung des
PLAYOUT Chip Planner
gearbeitet.
Aufgabe II: Entwurfsmanagement und Werkzeugintegration
Unsere langfristigen Arbeiten zu dieser Teilaufgabe fallen unter den weiter gefaßten Begriff der CAD-Frameworks. Diese umfassen alle Arbeiten, die helfen, neue Werkzeuge zu entwickeln und in ein CAD-System zu integrieren, sowie Arbeiten, die dem Chip-Designer den IC-Entwurf erleichtern. Wir beschäftigten uns hier im wesentlichen mit der Entwurfstheorie, der Datenhaltung, dem Entwurfsmanagement und der Wiederverwendung von Datenobjekten. Die Arbeiten zur Datenhaltung wurden zeitweise im Rahmen des übergreifenden Teilprojekts B7 ausgeführt und sind maßgebliche Vorarbeiten für einige Aspekte des neuen SFB 501.
Aufgabe III: Volumenvisualisierungsarchitektur
Ursprünglich dienten die im Teilprojekt entwickelten Beispielarchitekturen
im wesentlichen als Testumgebung für das PLAYOUT Entwurfssystem.
In diesem Rahmen wurde zu Beginn des SFB ein Parallelrechner
zur Unterstützung von Expertensystemen, die PESA, entworfen.
Der Entwurf erstreckte sich bis zum Layout und dessen detaillierten Simulation.
Etwa 1991 hatten wir uns entschlossen, die Entwicklung der PESA einzustellen
und ein Nachfolgeprojekt zu beginnen. Wir begannen, eine Spezialarchitektur
zur Volumenvisualisierung medizinischer Daten zu entwickeln,
da diese Aufgabe im Bereich der Medizintechnik hochaktuell war (und immer noch ist).
Eine vollständige Prototypentwicklung erschien uns bereits zu jenem Zeitpunkt
im Bereich der Visualisierung erfolgversprechender als auf dem Gebiet der Expertensysteme.
Unter Verwendung eines vereinfachten Raytracing-Algorithmus soll die
Volumenvisualisierungsarchitektur in der Lage sein, etwa 20 Bilder pro Sekunde zu berechnen,
um eine Rotation des Volumens in Echtzeit darstellen zu können.
In den beiden letzten Förderungsperioden wurden zwei Architekturansätze
entwickelt und weitgehend in Hardware realisiert.
Neben der Visualisierung haben wir an neuen Lösungen zur Segmentierung der Daten gearbeitet.
Die Segmentierung ist wichtig, um den hohen Informationsgehalt der Volumendaten
überhaupt adäquat visualisieren zu können.
Hier wurde ein spezielles, kantenorientiertes Bereichswachstumsverfahren entwickelt.
Der Wegfall von zwei Mitarbeitern gegenüber der vorangegangenen Förderungsperiode betraf im wesentlichen die Entwicklung des PLAYOUT-Entwurfsystems. Dieses wurde in der aktuellen Förderungsperiode noch insoweit gewartet, wie es für die abschließenden Arbeiten auf den Gebieten Abschätzung, Chip Planning und CAD-Frameworks notwendig war. Es fanden jedoch keine weiteren, größeren Entwicklungsarbeiten mehr statt. Ohne Reduktion, sowohl im Personalbestand als auch bei den Investitionen, wird bis zum Ende der Förderungsperiode die Entwicklung der DIV2A betrieben. Wir sind optimistisch, im Rahmen des SFBs einen lauffähigen Prototyp vorweisen zu können.
Im Berichtszeitraum wurden bis zur Fertigstellung dieses Abschlußberichts zwei Promotionen und eine Habilitation abgeschlossen. Drei weitere Promotionen sind bis Ende 1997 und eine vierte für Anfang 1998 geplant.
Die Qualität des top-down Chip Planning steht und fällt mit der Qualität der Abschätzung. Hierbei sind Zellfläche, Verzögerungszeiten und Leistungsaufnahme möglichst gut und möglichst früh im Entwurf abzuschätzen. Im Rahmen des Chip Planning-Projektes haben wir uns daher frühzeitig mit der Abschätzung beschäftigt. Zunächst hatten wir uns dabei auf die Flächenabschätzung mit Hilfe von Flächen- bzw. Formkurven (shape functions) konzentriert, da für deren Qualität die mittlere Schätzgenauigkeit ausreicht. In den letzten beiden Förderungsperioden wurde dieses Abschätzverfahren in 2 Richtungen erweitert: zum einen versuchen wir nun auch Netzlängen abzuschätzen um verläßlichere Aussagen über Verzögerungszeiten treffen zu können und zum anderen wurden die Toleranzen bei der Schätzung näher untersucht. Beides soll in diesem Abschnitt dargestellt werden. Zuvor findet sich jedoch eine Zusammenfassung über unser PLAYOUT-Entwurfssystem.
Kern dieses Teilprojektes ist das top-down Chip Planning, wofür seit Beginn der Förderung des Teilprojektes ein entsprechendes Werkzeug vorhanden war. Ausgehend von einer Vorgängerversion SPIDER, an deren Entwicklung der Antragsteller vor seiner Tätigkeit im SFB beteiligt war, entwickelte sich der PLAYOUT Chip Planner in mehreren Versionen zu einer größeren Toolbox, die mittlerweile zur sechsten Version erweitert wird.
Zur Realisierung unserer allgemeinen top-down Planungsmethode über beliebig viele Hierarchieebenen bedarf es neben diesem Werkzeug zur Plazierung, Verdrahtung und Analyse noch einer Abschätzung für die zu plazierenden, noch nicht realisierten flexiblen Zellen. Die Beschreibung der Subzellflächen durch parametrisierte Hyperbeln, wie sie bei SPIDER und der ersten Version des PLAYOUT Chip Planner verwendet wurden, wurde zur besseren Unterstützung des hierarchischen Vorgehens durch Treppenkurven ersetzt [Zim88.2]. Basierend auf diesen neuen Beschreibungsfunktionen und dem hierarchischen Ansatz wurde ein Werkzeug zur bottom-up Flächenabschätzung - Flächenfunktionsgenerator SFG (shape function generator) genannt - implementiert, das rekursiv vor dem eigentlichen Chip Planning auf allen Hierarchieebenen eingesetzt wird.
Der formabhängige Flächenbedarfs einer (Teil-) Schaltung wird dabei unabhängig von der tatsächlichen Plazierung ihrer Komponenten abgeschätzt. Dazu werden Flächenfunktionen (shape functions) aufgestellt, die die minimale Höhe einer Zelle in Abhängigkeit von der Breite angeben. Die effiziente Berechnung der shape functions ist mit geringen Toleranzen möglich [Zim90]; diese Toleranzen sind jedoch unvermeidbar, da über die genauen Netzverläufe nur statistische Annahmen gemacht werden können. Zur Zeitabschätzung trägt der SFG im Entwurfsablauf dadurch bei, daß er an die Kanten des zur Schaltung gehörenden Timing-Graphen Informationen über die abgeschätzten Netzlängen schreibt, die in eine genauere Timing-Analyse einfließen. Der Flächenfunktionsgenerator und der PLAYOUT Chip Planner wurden bis heute weiterentwickelt, um die neuesten Ideen im Bereich Abschätzung und Planung zu unterstützen.
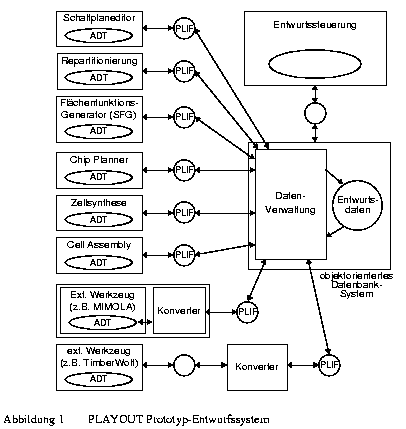
Zur Verifikation der Arbeiten in den Bereichen Abschätzung und Chip Planning wird ein vollständiges Entwurfsystem benötigt, das an den top-down Entwurfsprozeß angepaßt ist. Es werden sehr große, hierarchisch beschriebene Schaltungen als Testbeispiele benötigt, für die nach dem Chip Planning gute Layout passend zu den nach der Planung vorhandenen Floorplans und Rahmenvorgaben erzeugt werden müssen. Da dem Teilprojekt kein solches Entwurfssystem zur Verfügung stand, waren wir gezwungen, ein entsprechendes Prototypsystem selbst zu entwickeln. Das in der letzten Förderungsperiode fertiggestellte PLAYOUT-Entwurfsystem ist in Abbildung 1 dargestellt. Es besteht aus mehreren von uns entwickelten Toolboxes, die über eine zentrale Datenbank und ein eigenes Datenformat PLIF kommunizieren. Neben den in Abbildung 1 eingezeichneten Werkzeugen sind Fremdwerkzeuge bzw. Systeme wie beispielsweise MIMOLA und TimberWolf in PLAYOUT eingebunden.
Zur Erzeugung großer, hierarchischer Schaltpläne dient uns das high-level Synthesesystem MIMOLA, die Logiksynthese aus OASIS sowie ein von uns in zwei versionen implementierter Schaltplaneditor. Im allgemeinen startet der Entwurf mit PLAYOUT bei der Eingabe einer Verhaltensbeschreibung auf Prozessorebene in der Hardwarebeschreibungssprache MIMOLA, die in ihrer Zielsetzung ihren bekannteren Verwandten VHDL und Verilog ähnelt. Die Struktursynthese wird dann auf dieser Ebene mit dem MIMOLA Software System (MSS) durchgeführt. Noch nicht vorhandene Subzellen können daraufhin auf den tieferen Hierarchieebenen mit den anderen Struktursynthesen generiert werden.
Da die von diesen Werkzeugen erstellten hierarchischen Netzlisten meist sehr regulär, mit einer sehr tiefen Hierarchie und nicht an die physikalischen Entwurfswerkzeuge angepaßt sind, ist ein Repartitionierungsschritt notwendig, der die hierarchische Partitionierung der Gesamtschaltung an den physikalischen Entwurf anpaßt, ohne die Netzlisteninformation zu verändern. Dieses Problem ist relativ neu und immer noch Stand der Forschung. Im PLAYOUT-System wurden hierfür drei Versionen eines interaktiven Repartitionierungswerkzeuges entwickelt, die über die Jahre unsere zunehmenden Erfahrungen im Bereich der Repartitionierung in Form von verbesserten Partitionierungsalgorithmen und Analysen repräsentierten. Den momentanen Abschluß unserer Arbeiten im Bereich der Repartitionierung erfolgte mit den Implementierungsarbeiten zu der Promotion von Hebgen [Heb95]. Heute stehen uns als Verfahren automatische Teilpartitionierungen und interaktive Repartitionierung an einem exemplarischen Flächenplan zur Verfügung. Berücksichtigt werden folgende Faktoren: ausgewogene Größenverhältnisse der Zellen auf einer Hierarchieebene; geeignete Anzahl von Zellen für das nachfolgend eingesetzte Werkzeug des physikalischen Entwurfs (z. B. mehrere Tausend Zellen für den Standardzellenplazierer, 10 - 100 Zellen für den Chip Planner); günstige Schnitte zwischen den Partitionen, die möglichst wenige und zeitunkritische Netze treffen. Kombiniert ist die Repartitionierung mit einer Timing-Analyse, die erste Zeitabschätzungen für den weiteren physikalischen Entwurf liefert [Heb95].
Nach der Repartitionierung einer Schaltung erfolgt die Flächenabschätzung, das Chip Planning und abschließend das Chip Assembly, bestehend aus einer Zellsynthese und dem Cell Assembly (Abbildung 2). Beides wurde im Rahmen der Promotion Glasmacher realisiert [Gla92]. Zur Zellsynthese von Standardzellblöcken dient meist eine an TimberWolf [SeS85] angelehnte Implementierung von Simulated Annealing, bei der Vorgaben für Pinpositionen berücksichtigt werden. Um zu zeigen, daß die Planung auch Vorgaben für unterschiedliche Syntheseverfahren erzeugen kann, wurde darüber hinaus ein analytisches Verfahren zur Standardzellplazierung [Die96] in PLAYOUT integriert. GORDIAN [KSJ91] und der Einsatz von Modulgeneratoren wären an dieser Stelle ebenfalls denkbar.
Auf den höheren Hierarchieebenen wurde zur Legalisierung und Optimierung der Layouts nach Vorgabe durch die Floorplans eine Werkzeugumgebung zum Cell Assembly implementiert. Die Layout-Optimierung wird durch einen in B4 entwickelten genetischen Algorithmus durchgeführt. Für die Pinplazierung und die Detailverdrahtung wurden geeignete Algorithmen aus der Literatur angepaßt.
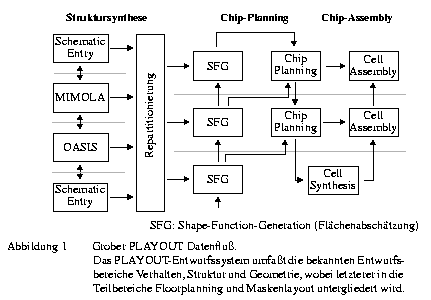
Mit Hilfe dieses PLAYOUT-Entwurfsystems wurden immer wieder größere Testentwürfe bis zum Layout durchgeführt (z.B. [Sur92]). Zur Unterstützung dieser Entwürfe wurden die Werkzeuge des PLAYOUT-Systems in ein selbstentwickeltes CAD-Framework mit zentraler Entwurfsdatenbank und einer Entwurfssteuerung eingebettet. Das PLAYOUT-Framework wird weiter unten noch näher beschrieben.
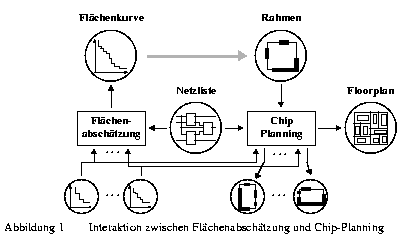
Zur Beschreibung des Flächenbedarfs gibt es verschiedene Ansätze. Da die Fläche einer Schaltung von der Form des Layouts abhängt, ist es ratsam, nicht nur eine Größenangabe für eine Zelle zu machen, sondern differenzierter für jede mögliche Form (zumindest für viele verschiedene, in der Realität vorkommende Formen) die Größe zu schätzen. Eine hierfür mögliche Beschreibungsform ist die in Abbildung 4 gezeigte Flächenkurve, die sich in der Literatur mittlererweile durchgesetzt hat [Ott83, Zim88.2]. Eine solche Flächenkurve beschreibt für eine gegebene Breite einer Zelle (X-Achse) die zugehörige minimale Höhe der Zelle (Y-Achse). Die Kurve bildet damit die Grenze zwischen allen realisierbaren Flächen (oberhalb der Kurve) und einem nicht realisierbaren Bereich (unterhalb der Kurve). Man kann sich leicht überlegen, daß die Kurve monoton fallend sein muß. Alle bekannten Verfahren verwenden heute treppenförmige Kurven, wie sie in der Abbildung zu sehen sind, da mit ihnen leicht gerechnet werden kann. Aufgrund der Schätztoleranzen sind solche Treppenkurven vollkommen ausreichend. Die Zahl der Treppenstufen reicht dabei von Eins (festes Layout mit einer Form, z. B. Standardzellen) bis zu etwa Hundert (flexible Zelle auf etwa 1% Genauigkeit approximiert).
Wir unterscheiden drei Arten von Zellen, die durch die Flächenkurven beschrieben werden: Makros, Multimakros und flexible Zellen. Makros haben nur ein festes Layout. Dies können Speicherbausteine oder Standardzellen fester Form, d. h. Bibliothekszellen, oder aber auch Layouts früherer Entwürfe sein. Der einzige Eckpunkt in der zugehörigen Flächenkurve beschreibt die Ausdehnung des Layouts. Liegen mehrere Layoutalternativen zur Verfügung, von denen später eine ausgewählt werden kann, so sprechen wir von Multimakros. Zu jeder dieser Layoutalternativen hat die Flächenkurve im allgemeinen einen Eckpunkt. Eine Layoutalternative wird nur dann nicht in der Flächenkurve berücksichtigt, wenn sie in beiden Dimensionen größer als eine andere Alternative ist. Trotzdem kann sie später für die Anwendung interessant sein, wenn z. B. trotz größerer Fläche die Pinpositionen oder das Zeitverhalten günstiger ist. Die Unterscheidung zwischen Makros und Multimakros hat rein technische Gründe. Da Makros mit nur einer Form einen Spezialfall der Multimakros darstellen, genügt es theoretisch, nur die Multimakros zu betrachten. Die letzte Klasse sind die flexiblen Zellen. Hierunter fallen alle Zellen, deren Layout noch nicht vorliegt. Sie sind die wichtigste Klasse im TD-Entwurf. Für diese Zellen gibt es zur Zeit der Planungsphase nur geschätzte Flächenkurven. Jeder Kurvenpunkt hat Toleranzen in beiden Dimensionen. Die ganze Kurve wird von einem Toleranzband umgeben. Es macht daher keinen Sinn, eine zu feine Treppenkurve zu wählen.
Wie bereits erwähnt, schränken wir die Topologie auf Slicing-Strukturen ein. Es wurde gezeigt, daß diese Einschränkung der Layout-Geometrien kaum Einfluß auf die Qualität eines Floorplan hat. Andererseits wird dadurch das Chip-Planning wesentlich vereinfacht. Beispielsweise läßt sich der Floorplan in diesem Fall einfach durch einen binären (Slicing-) Baum darstellen (siehe Abbildung 4). Andere Geometrien können dagegen nur mit komplexeren Graphen dargestellt werden.

Die Wurzel des Slicing-Baums aus Abbildung 4 repräsentiert die Topologie der gesamten Zelle C, die CUD (Cell Under Design) genannt wird. Die Subzellen von C werden durch die Blätter repräsentiert. Jeder innere Knoten gehört zu einer Schnittkante, die zwei Teilflächen verbindet. Sind die Flächenkurven für die Blätter eines Slicing-Baums bekannt, so können diese einfach bottom-up im Baum aufaddiert werden, bis die Flächenkurve (die Flächenschätzung) des Wurzelknotens C berechnet ist [Ott83].
Die Flächenkurve der Wurzel, d. h. der Gesamtzelle C, beschreibt den Gesamtflächenbedarf nur dann korrekt, wenn keine Verdrahtungsfläche zur Verbindung der Subzellen benötigt wird. In den allermeisten Fällen wird diese Verdrahtungsfläche jedoch nicht zu vernachlässigen sein. Da zur Zeit der Flächenabschätzung weder die Topologie des Floorplan bzw. Layouts noch die Pinpositionen der Subzellen vorliegen, kann die benötigte Verdrahtungsfläche auch nur geschätzt werden [KuP89, Zim88.2]. Wir verwenden hierfür ein rekursives Schätzmodell, das auf empirisch ermittelten Flächenbedarfsfaktoren beruht. Abhängig von diesen Faktoren und der Richtung der Schnittkanten im Slicing-Baum wird der Verdrahtungsflächenbedarf ermittelt. Dabei werden auch Leerflächen und existierende Verdrahtungswege über die Subzellen berücksichtigt. Das Verfahren hat einen mittleren Schätzfehler von etwa 10% und kann in [Zim88.2] und [SuZ92] nachgelesen werden.
Unsere Experimente und Messungen haben gezeigt, daß die Verdrahtungsfläche sehr stark von den Qualität der Plazierung und den Pinpositionen abhängt [SuA95]. Da diese während der Flächenabschätzung noch nicht vorliegen, wird ein zweistufiges Schätzverfahren verwendet. Während der BU-Schätzphase wird auf die Pinpositionen keine Rücksicht genommen. Es wird lediglich die minimale Layoutfläche bei gegebener Form geschätzt. Flächenzuschläge aufgrund von Pinrestriktionen werden erst später während der TD-Chip-Planning-Phase hinzugefügt, wenn die Positionen, die durch das Chip-Planning festgelegt werden, bekannt sind. Auch muß die während der Schätzphase angenommene Slicing-Topologie nicht mit der Topologie des späteren Floorplan bzw. Layouts übereinstimmen. Diese Differenzen können durch geänderte Schätzfaktoren angepaßt werden.
In [Heb95] wurde eine Abschätzung von Netzlängen in das PLAYOUT-System integriert, um für neuere Technologien die notwendig gewordene Zeitbehandlung durchführen zu können. Während zu Beginn des SFB noch die Minimierung von Flächen an erster Stelle stand und für Verzögergungszeiten auf Pfaden die der Basiszellen ausreichend waren, fällt mit nun geringer werdenden Leiterbahnbreiten die Minimierung der Netzlängen auf dem kritischen Pfad ein sehr großes Gewicht zu. Wir konnten zeigen, daß eine Abschätzung der Netzlängen, basierend auf eine Bipartitionierung der zugrunde liegenden Schaltung, erfolgsversprechend ist. Wie sich jedoch gezeigt hat, kann man nicht mit den Längen selber arbeiten, sondern muß diese als Repräsentant für eine Klasse von Netzlängen nehmen. Unsere aktuellen Arbeiten zeigen, daß die Abschätzung kritischer Pfade möglich ist. Um jedoch statistisch sichere Aussagen über die Toleranzen machen zu können, werden bis Ende der Förderungsperiode noch weitere Entwürfe ausgewertet.
Die zweite Erweiterung des Flächenfunktionsgenerators bestand im Hinzufügen von Partitionierungsalgorithmen. Hier sollte untersucht werden, wie sich unterschiedliche Partitionierungsstrategien auf die Flächenvorgaben auswirken. Zu dem bisher einzigen Partitionierungsverfahren nach [FiM82] wurden der Ratio Cut Ansatz nach [WeC91.1], die spektrale Methode [Dem97] nach [HaK92] und die in [DuD96] vorgestellten Verfahren integriert. Hiermit konnte gezeigt werden, daß die Flächenabschätzung gegenüber dem Einfluß unterschiedlicher Partitionierungsverfahren stabil ist.
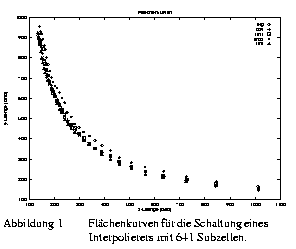
Abbildung 5 zeigt beispielhaft die Flächenkurven für die 5 unterschiedlichen Bipartitionierungen. Da es sich bei der Abschätzung um einen Standardzellentwurf handelt, wurde die Anzahl möglicher Formvorgaben durch Begrenzung auf Zeilen reduziert. Ferner wurden keine Seitenverhältnisse größer als 1:7 betrachtet. Da bei der Abschätzung mit dem Flächenfunktionsgenerator die Positionen der Außenanschlüsse nicht berücksichtigt werden (dies kann erst bei der Planung erfolgen), wird eine Gleichverteilung der Anschlüsse angenommen. Eine gute Näherung für den Flächenaufschlag zur Berücksichtigung der Außenanschlüsse ergibt sich aus dem Seitenverhältnis.
Um Aussagen über Toleranzen in der Abschätzung statistisch untermauern zu können, wurden die drei Chips für den Voxelprozessor für PLAYOUT umgesetzt. Neben der Einbindung einer modernen Standardzellbibliothek [Ham96] in das PLAYOUT-Entwurfssystem, wurden die mit Mentor erzeugten Netzlisten nach PLIF konvertiert [Sie88]. Dies war notwendig geworden, um PLAYOUT an realen Beispielen zu testen und um neben dem möglichen Papierentwurf gefertigte Chips als Vergleichsdaten zu erhalten.
Nach der Repartitionierung [Heb95] in eine layoutgerechte Struktur mit 2 Ebenen wurde die Planung durchgeführt. Für die Zellen auf unterer Ebene erfolgte die Synthese mit beiden oben erwähnten Verfahren und eine Vielzahl unterschiedlicher Parameter. Abbildung 6 zeigt beispielhaft die Verteilung aller 2-Punkt-Netze der Schaltung des Interpolierers. Bis Ende der Förderungsperiode werden wir die Verteilung der Netzlängen und deren Parameter aus unseren Beispielentwürfen bestimmt haben. Die Parameter dieser Verteilungen sind dann Ergebnisse der Abschätzungen der Toleranzen.
Nach Auswahl einer Formvorgabe auf oberster Hierarchieebene wird mit dem Chip Planner als Floorplanning-Werkzeug die top-down Planung über alle Ebenen durchgeführt. Mit Algorithmen zur Plazierung und globalen Verdrahtung legt er die Form der Subzellen und die Positionen ihrer Anschlüsse fest, die als Eingabe für die nächst tiefere Ebene dienen. Die Ziele sind möglichst kleine Chipfläche und minimale Verzögerungszeiten. Die Verfahren zur Optimierung der Signallaufzeiten wurden dabei erst in jüngerer Zeit in die Algorithmen zur Plazierung und Verdrahtung aufgenommen. Die Ziele lassen sich in drei Teilziele aufspalten:
1. Kurze Verbindungswege zwischen den Zellen, insbesondere räumliche Nähe
bei der Plazierung von Subzellen auf zeitkritischen Pfaden
2. Verminderung von Verschnittfläche
3. Auswahl von Zellformen minimaler Fläche (bei flexiblen Subzellen).
Um den Lösungsraum einzuengen und effizientere Algorithmen einsetzen zu können, wurden die möglichen Flächenaufteilungen auf Slicingstrukturen eingeschränkt. Ein Slicingbaum zeigt die relative Anordnung (Topologie) der Zellen zueinander und jedem Zwischenknoten im orientierten Slicingbaum kann eineindeutig eine horizontale oder vertikale Slicingkante im Floorplan zugeordnet werden. Mittels Ordnung und Sizing wird aus der Topologie eine (abgeschätzte) Topographie oder Geometrie.
Für die Plazierung unter dem alleinigen Gesichtspunkt der Flächenminimierung hat sich ein dreigeteiltes Verfahren, bestehend aus rekursiver Bipartitionierung, (horizontal/vertikal)-Orientierung und (links/rechts)-Ordnung bewährt. Für die Verwendung von Verzögerungszeitinformation wurde ein einstufiges Verfahren zur Plazierung flexibler Zellen mittels rekursiver Bipartitionierung mit Terminal Propagation neu implementiert.
Das frühere Plazierungsverfahren [Sur88] begann mit einer rekursiven Bipartitionierung durch einen Cluster-, Mincut- oder Inplace-Partitionierungs-Algorithmus [PaZ90]. Anschließend wurden Sizing und (h/v)-Orientierung mit dem Verfahren der optimalen Überlagerung [Zim88.2] (stets horizontale und vertikale Addition der Sizingkurven beider Teilbäume und Auswahl der kleineren Fläche) kombiniert. Schließlich entschied die (l/r)-Ordnung durch vollständige Enumeration aller zulässigen Anordnungsmöglichkeiten in einem Suchfenster, welcher von zwei Nachbarn im Slicingbaum bei vertikaler Slicinglinie im Flächenplan links vom anderen und bei horizontaler Slicinglinie unterhalb des anderen zu liegen kommt. Optimierungskriterium war hierbei die abgeschätzte Gesamtnetzlänge (vor dem Global Routing).
Bei der globalen Verdrahtung (Global Routing) kommen als Optimierungsziele die Minimierung der Gesamtnetzlänge und die Minimierung der Gesamtfläche in Betracht. Unter einem Netz sind die Verbindungen von zwei oder mehr Anschlüssen (Pins) verschiedener Zellen zu verstehen. Die mögliche Verbindungswege werden durch Graphen repräsentiert, so daß sich die Aufgabe, die Gesamtleitungslänge eines Netzes zu minimieren, als Suche nach kürzesten Wegen in Graphen darstellt. Bei der Minimierung der Gesamtfläche wird versucht, über eine geeignete Kapazitätsmodellierung der Kanten im Graphen eine ausgewogene Nutzung der Verdrahtungsregionen zu erreichen. Für die Algorithmen zur Signalwegeplanung sei auf den zweiten Teilabschnitt von 3.1.6 verwiesen.
Nach der Signalwegeplanung, d. h. der Zuweisung der Verbindungswege zu den Kanten des Verbindungsgraphen, erfolgt als zweiter Schritt im Global Routing die Kanalflächenberechnung, d. h. die Umrechnung der einer Kante zugeordneten Netzanteile in Verdrahtungsflächenanteile. Durch diese Kanalflächenberechnung ergibt sich eine genauere Abschätzung der für die Verdrahtung benötigten Fläche als vor dem Global Routing möglich war, deshalb wird anschließend ein Sizing mit diesen genaueren Werten durchgeführt. Es ergibt sich dadurch eine Schleife von Global Routing und Sizing, da das Global Routing stets auf "veralteten" Werten aus dem Sizing arbeitet, jedoch ergibt sich in der Praxis schnell eine Konvergenz.
Beim Global Routing wird auch das Pin Assignment, also das Festlegen von günstigen Anschlußpositionen (Pin-Intervallen) flexibler Subzellen bzw. die Auswahl äquivalenter Anschlußpositionen bei Makrozellen durchgeführt.
Messungen und die jahrelange Entwurfserfahrung [Sur92] mit dieser Methodik haben gezeigt, daß bei den Flächenabschätzungen mit verfahrensbedingten Toleranzen im Bereich von 5 - 10%,die die Vorteile des top-down Ansatzes zunichte machen können, zu rechnen ist. Um damit umgehen zu können, wurden in dem Modell des 3-Phasen Chip Plannings [SAZ92] Abgleichschritte nach oben und unten (in der Hierarchie) aufgenommen. Hierbei führen wir neben dem Planungsschritt der einfachen top-down Planung (Phase alpha) Anpassungsschritte an eine verfeinerte Rahmenbeschreibung (in der Phase beta) und an die verfeinerten Daten der Subzellen (in der Phase gamma aus (siehe Abbildung 3). Da nicht notwendigerweise die Phase alpha für alle Subzellen durchgeführt werden muß, bevor ein Abgleich mit der CUD erfolgt, existieren verschiedene Strategien des 3-Phasen Chip Planning, die in den angegebenen Publikationen näher untersucht wurden.
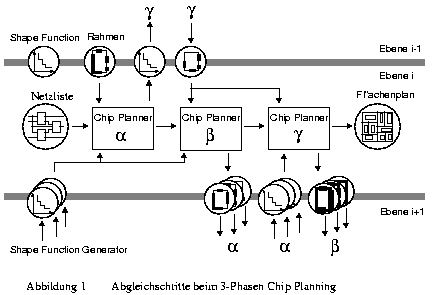
In mehreren Testentwürfen konnten wir zeigen, daß der Flächengewinn beim 3-Phasen Chip Planning gegenüber der einfachen top-down Methode etwa 5 bis 10% beträgt. Dies hängt jedoch stark von dem Verhältnis flexibler Zellen zu Makrozellen ab. Bei vielen flexiblen Zellen konnten die oben erwähnten Gewinne erzielt werden, während bei Planungen mit fast ausschließlich festen Makrozellen (was jedoch unserem top-down Ansatz widerspricht) sich praktisch keine Verbesserungen einstellten. Dies liegt darin, daß die Flächenpläne mit vielen Makrozellen bei den ersten Planungsschritten (alpha und beta) recht viel Verschnittfläche enthielten, die zur Kompensation genutzt werden konnte.
Der hierarchische top-down Entwurf stellt - wie wir gesehen haben - spezifische Anforderungen an die Entwurfswerkzeuge. So bilden Abschätzungen und Arbeiten mit physikalischen Restriktionen einen wesentlichen Aspekt beim hierarchischen Entwurf. Auf der Seite der CAD-Algorithmen für den VLSI-Entwurf stellen sich interessante Fragen im Hinblick auf ihr Ergebnisverhalten, da ein stabiles Ergebnisverhalten notwendig ist, um das Planen mit Toleranzen durchführen zu können. So war die Implementierung, Bewertung und Weiterentwicklung der Algorithmen stets eine wichtige Aufgabe bei unserem Planungsansatz für den Chipentwurf.
Timing-driven Placement im Chip Planner
Auch die zeitgesteuerte Plazierung arbeitet mit rekursiver Bipartitionierung nach der divide-and-conquer Strategie. Zunächst werden die Subzellen durch einen horizontalen oder vertikalen Schnitt auf oberster Ebene in zwei annähernd flächengleiche Partitionen aufgeteilt. Sowohl hier wie auf allen tieferen Ebenen werden Partitionen für beide Schnittrichtungen berechnet, bewertet und die Partition mit dem günstigeren Ergebnis bestimmt die Schnittrichtung. Die Unterschiede in den Partitionen bei anderer Schnittrichtung ergeben sich dadurch, daß als Bipartitionierungsverfahren die Inplace-Partitionierung mit Mincut- oder Ratiocut-Kostenfunktion und Terminal Propagation angewendet wird.
Das Terminal Propagation-Verfahren konstruiert auf einer abgeschätzten Geometrie rechtwinklige Steinerbäume (RST = rectilinear Steiner tree) für die zu verdrahtende Netze. Diese können zusätzliche Knoten mit Fläche Null (Dummy-Knoten) erzeugen, die fest an eine Partition gebunden sind.
Eine Zeitsteuerung ist bei unserem Verfahren durch Netzgewichtung, durch Selektion zu berücksichtigender Netze oder durch Grenzen für Netz- bzw. Pfadlängen (berechnet im Global Routing) möglich. Die Optimierung des Zeitverhaltens und die Minimierung der Gesamtverdrahtungsfläche sind zwei Ziele, die zueinander in Konflikt stehen können, so daß für ein optimales Zeitverhalten mitunter eine leicht größere Gesamtfläche in Kauf genommen werden muß.
Die rekursive Bipartitionierung findet auf einem Hypergraphen statt, in dem die Knoten für die Subzellen und die Hyperkanten für die Netze stehen; sie führt zu einer Slicing-Topologie
Das Terminal Propagation-Verfahren von [DuK85] wurde auf den Anwendungsfall flexibler Subzellen angepaßt [Fri96] und anstelle der Partitionierung mit dem Kernighan / Lin-Algorithmus [KeL70] stehen die Partitionierungsalgorithmen von Fiduccia / Mattheyses [FiM82] und Wei / Cheng [WeC91] zur Verfügung. Letzterer benutzt anstelle der Mincut-Kostenfunktion die Ratio Cut-Kostenfunktion, die die Ausgeglichenheit der Partitionen implizit berücksichtigt. Für dieses Kriterium wurde bei der Mincut-Partitionierung eine Balancebedingung [Saf96.1] zusätzlich eingeführt. Die Kernidee beim Terminal Propagation-Verfahren ist die Berücksichtigung des Einflusses von Signalnetzen, die von außerhalb in die zu partitionierende Teilschaltung eingehen (und nicht nur von internen Verbindungen), bei der Ermittlung der Schnittkosten.
Auf oberster Ebene steht Ortsinformation über externe Pin-Anschlüsse der CUD zur Verfügung. Auf tieferen Ebenen hat man zusätzlich Angaben über mögliche Bereiche, in denen andere Zellen, die nicht zur gerade betrachteten Menge gehören, zu liegen kommen können. Die Ortsinformation wird folgendermaßen präzisiert:
Abweichend von [DuK85] lassen wir für die externen CUD-Anschlüsse Intervalle zu, die für die Propagierung auf genau eine definierte Position, z. B. den Mittelpunkt reduziert werden, falls sie nicht überhaupt zu groß ausfallen. Da über Zellen anderer Partitionen über die Partitionszugehörigkeit hinaus keine genauen Informationen zur Verfügung stehen, werden sie mit dem geometrischen Mittelpunkt ihrer Partition (d. h. der damit assoziierten Teilfläche der CUD) identifiziert.
Die auf diese Weise definierten externen Anschlußpunkte eines Netzes werden zum Rand der aktuellen Partition propagiert und induzieren dort fixierte Dummy-Knoten, die bei der nachfolgenden Bipartitionierung eine feste Partitionszugehörigkeit aufweisen und so das Ergebnis beeinflussen.
Die Propagierung erfolgt so: Zu jedem betrachteten Netz mit Anschlüssen / Terminals innerhalb und außerhalb der aktuellen Partition bildet man einen Low-cost-Steinerbaum über allen (approximierten) Anschlußpositionen zur Approximation der Verdrahtung dieses Netzes. (Abweichend hiervon definiert [DuK85] den Steinerbaum nur über den externen Anschlußpunkten.) Die Schnittpunkte des Steinerbaums mit dem Rahmen der aktuellen Partitionsfläche heißen propagierte Terminals. Propagierte Terminals nahe der Mittellinie werden ignoriert, da eine Zuordnung zu einer der beiden zukünftigen Partitionen eher zufällig wäre.
Jeder Partitionierungsschritt erzeugt einen Knoten des Slicingbaums. Zur maximalen gegenseitigen Ausnutzung der Ortsinformation wird der Baum in Breitensuche aufgebaut.
Die oben angesprochene Anpassung dieses ursprünglich für Standardzellenentwürfe entwickelten Verfahrens an flexiblen Subzellen geschieht folgendermaßen.
Der Slicingbaum spiegelt nicht nur die Topologie der Schaltung wider, er repräsentiert auch die Aufteilung der Gesamtfläche entsprechend der Slicingstruktur auf Teilbäume und Blattzellen. Bei jedem Partitionierungsschritt erfolgt die Aufteilung der zur Verfügung stehenden Fläche auf die beiden Teilbäume relativ zum Größenverhältnis der beiden Partitionen. Das Verfahren arbeitet dabei mit einer (abgeschätzten) Geometrie. Für jede Subzelle wird die kleinste realisierbare Fläche - unabhängig vom Aspect Ratio - und eine Hyperbel als Flächenfunktion angenommen.
Performance-driven Global Routing im Chip Planner
Die für die globale Verdrahtung zur Verfügung stehenden Routing-Bereiche werden durch einen erweiterten Eckpunktgraphen repräsentiert. Der einfache Eckpunktgraph (CG = corner graph) modelliert die Kanäle zwischen den Zellen. Er hat Kanten für die Randkanäle der CUD und für alle Slicinglinien. Für Durch-die-Zelle- und Überzellverdahtung wird er um zusätzliche Kanten erweitert.
Falls für eine Hierarchieebene zwei freie Verdrahtungsebenen (layer) zur Verfügung stehen, kann anstelle der Kanalverdrahtung nur Überzellverdahtung mittels Area Routing durchgeführt werden. In der hierarchischen Entwurfsmethodik wird dieses eher die Ausnahme sein und man muß Kombinationen aus Kanalverdrahtung und Durch-die-Zelle- / Überzellverdahtung unterstützen.
Als das einzige Optimierungsziel noch die Minimierung der Gesamtnetzlänge war, verfolgten wir folgende Strategie [Anh89.1]: Es wurden nacheinander alle Netze auf dem gleichen Graphen mit unbegrenzten Kantenkapazitäten verdrahtet. Dem lag das Modell zugrunde, daß die beim Sizing veranschlagten Verdrahtungsaufschläge in der Regel ausreichend groß sind, um alle einer Kante zugeordneten Netze aufnehmen zu können oder anderenfalls beim erneuten Sizing nach der globalen Verdrahtung entsprechend erhöht werden und dann in die oben beschriebene Schleife von globaler Verdrahtung und Sizing einfließen.
Die Schwäche dieses Verfahrens lag darin, daß in der Regel die Kanäle in der Mitte des Chips sehr voll wurden und die weiter am Rand eher leer blieben. Dieses wird durch dynamische Kanalkapazitäten und prioritätsgesteuertes Routing vermieden. Netze geringerer Priorität werden eventuell in äußere Kanäle gezwungen, wodurch sich ihre Netzlänge etwas erhöht, aber durch die gleichmäßigere Auslastung der Kanäle die Gesamtfläche der Layouts kleiner gehalten wird. Deshalb ist - neben dem Einhalten der Zeitbedingungen - das Optimierungsziel jetzt die Minimierung der Gesamtfläche. Um dieses zu erreichen, werden Verfahren für die dynamische Anpassung der Kanalkapazitäten implementiert und Kriterien für kritische Kanäle aufgestellt.
Zur Minimierung der maximalen Pfadverzögerungszeit wird die kleinste Differenz aus geforderter und berechneter Signalankunftszeit an allen Signalsenken maximiert. Die Signalankunftszeiten werden mit einer Timing Analyse auf dem zur Schaltung aufgestellten Timing Graphen (Signal Propagation Graphen) ermittelt. Untersucht wird auch der Trade-Off zwischen diesen beiden Zielen.
Des weiteren ist eine enge Kopplung an die zeitgesteuerte Plazierung notwendig, da das Routing alleine wenig Freiheiten hat, um die Einhaltung von Zeitbedingungen bei groben Verstößen zu erzwingen. Eine Möglichkeit ist der Einbau von Treibern (Buffer Insertion) in zu kurze oder zu lange Leitungen. In zu kurzen Leitungen kann eine verfrühte Signalankunft verhindert werden. Bei sehr langen Netzen kann unter Umständen die Signalankunft beschleunigt werden. Hierzu wird der "Break-Even-Point" bestimmt, d. h. der Punkt, ab dem die zusätzliche Verzögerungszeit durch den Treiber hindurch aufgewogen wird durch die Wirkung.
Für Zwei-Punkt-Netze wird auf dem erweiterten Eckpunktgraphen mit dem Algorithmus von Dijkstra der kürzeste Weg gesucht und in polynomialer Zeit gefunden. Bei Mehr-Punkt-Netzen ist zu unterscheiden, ob man den kürzesten [Pop96] oder den kostenoptimalen [Fri97] Steinerbaum sucht. Im Hinblick auf das Zeitverhalten bedeutet kostenoptimal, daß der Weg von der Signalquelle zur zeitkritischsten Senke minimiert wird. Bei mehr als drei zu verbindenden Punkten ist man aus Effizienzgründen zur Lösung beider Aufgaben auf (unterschiedliche) Heuristiken [HwR92] angewiesen.
Zur Modellierung der Verzögerungszeiten wird auf das t0,7 - Delay-Modell von Horneber / Mathis [HoM87] für RC-Bäume zurückgegriffen, wie es auch bei der durchgeführten Timing-Analyse eingesetzt wird.
Neben dem Verlauf der Signalwege und der daraus berechneten Kanalflächenaufteilung ergeben sich aus der globalen Verdrahtung die Anschlußintervalle für die Pins der flexiblen Subzellen, die im Sinne des hierarchischen Entwurfs an die nächst tiefere Ebene gereicht werden.
Da wir insbesondere im Hinblick auf zukünftige Technologien, in denen die Signalverzögerungszeiten über die Netze ein erheblich höheres Gewicht erhalten, Aussagen über die Güte unseres Verfahrens treffen möchten, simulieren wir dieses dadurch, daß der Anteil, den die Verzögerungszeiten auf den Netzen an der Gesamtverzögerungszeit ausmacht, zusammen mit den anderen physikalischen Parametern skalierbar ist.
Eine weitere Arbeit beschäftigte sich in diesem Zusammenhang mit der Verdrahtung von Taktnetzen. Es wurde das Verfahren von Tsay [Tsa93] zum Entwurf von Taktnetzen ohne Taktschlupf (Zero Skew Clock Routing) an die Erfordernisse unseres Systems angepaßt [Kur96].
Mirror sites:


